Week 2: Github Part 2/ R Markdown / Programing Intro
Schedule
-
8:30 - 9:30 am
Github finish: Git lecture, II [15 min, NT] Assign env-info groups [5 min] Doodle preferred office hours for BB by 5pm today
Git Assignment (Group), to create Github organization and respository [30 min, per group] Rmarkdown lecture & demo [BB, 30 min] -
9:30 - 10:30 am
Break [10 min] RMarkdown Assignment (Individually) to add student listing [30 min, individually] Programming concepts lecture Programming Lecture [20 min, NT]
-
10:30 - 11:30 am
Programming exercise I [20 min, individually] More on Programming [20 min, NT] Programming exercise II [20 min, individually]
Github Demo II [NT]
# list git log in reverse order
git log --reverse
# go back in time
git reset #commit#
# go back and delete all subsequent commits!
git revert #commit# --hard
Assignment
Due: Jan 21, Thursday 5pm
Git Assignment (Group)
-
Assign yourself to an env-info group
-
The first person listed in the group should Create a new Github organization (eg
<organization>iswhaleroute) and Add organization members to the owner team (eg ownerbbestadds usernamenaomitague). -
The first person listed in the group should also Create a repository with Owner set to your organization (eg
whaleroute, not your default username) and name it after your Github<organization>.github.io(egwhaleroute.github.io). Tick the box to initialize this repository with a README.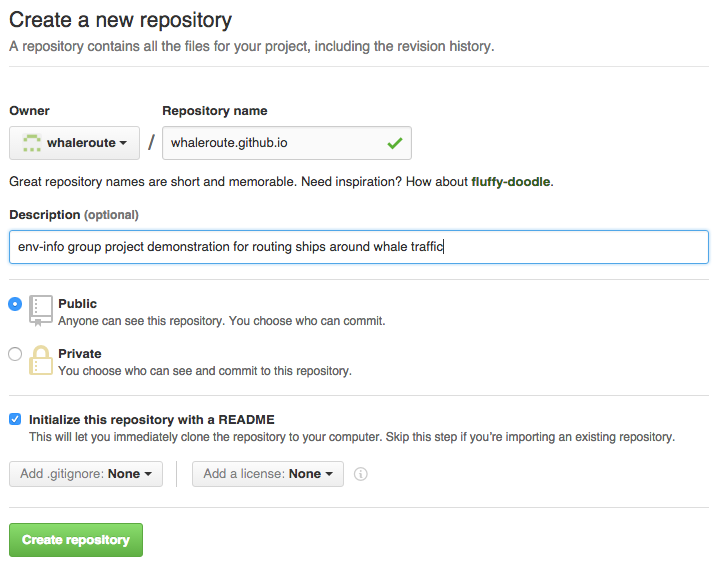
This repository will store your organization’s website files, so the repository of files at
http://github.com/<organization>/<organization>.github.io(eg http://github.com/whaleroute/whaleroute.github.io) will eventually be viewable athttp://<organization>.github.io(eg http://whaleroute.github.io), but only after you add an index.html, per pages.github.com. That will come later, after you learn RMarkdown. For now you’ll use this repository to work on your Git and Github skills. -
Now every member of the group should obtain this repository onto your local machine for editing, ie
git clone. You can do this via RStudio menu File, New Project…, Version Control, Git. Substitute with your own<organization>like below (notwhaleroute):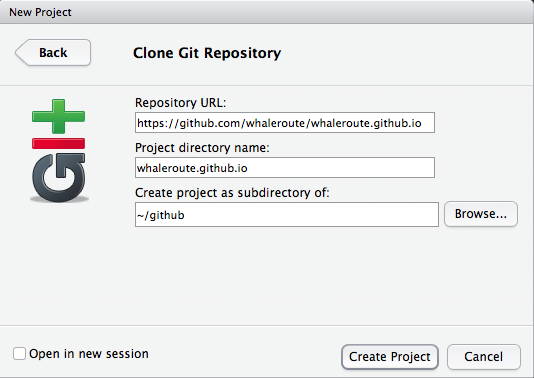
-
Finally, time to play with Git/Github in RStudio to make changes for your group’s data analysis.
- Write a short Rscript to read or generate some data, manipulate it and plot it
- Commit your file to the local repository and Push to the Github respository;
- Have everyone in the group make some changes to the script. Commit them locally and then Push to Github.
- Make a new branch, make some changes; commit them (locally)
- Merge your fork to the main branch
- Make an error, commit it
- Go back!
- Commit and push to Github
RMarkdown Assignment (Individually)
Add yourself to the students listing with a json 1 file, and a dedicated Rmarkdown document.
-
Fork the ucsb-bren/env-info repository into your Github user space, and clone the repository
<username>/env-infoto your laptop to work on files, similar to how you previously cloned<organization>/<organization>.github.io(via RStudio menu File, New Project…, Version Control, Git). All paths below refer to wherever you cloned theenv-inforepo onto your local machine. -
Add yourself the students listing by adding a file per your Github
<username>.jsoninto the_data/directory. Here’s an example for Github usernamebbest, so the file is at_data/bbest.json:{ "program": "lecturer", "interests": "marine ecology, species distribution modeling", "project": "route ships around marine mammal hotspots", "organization": "whaleroute" }Using the format above, replace with your own
program(eg"MS"or"PhD"),interestsandprojectidea. Leaveorganizationblank for now; you’ll update that once you’ve identified your group below.Commit and push your changes and make a new pull request. Once your new pull request gets accepted by @bbest / @naomitague, you should see the updated students listing with your organization linked to your
<organization>.github.io. -
The students listing generated from the *.json files (using jekyll 2 ) links your user information to a details page at
students/<username>.html. Create this using an Rmarkdown document (in RStudio, File > New File > R Markdown… Document in HTML format), so save it initially as<username>under thestudentsfolder and it will default to save as<username>.Rmd(iestudents/<username>.Rmd). Click the “Knit HTML” as you go to render thestudents/<username>.html.-
Add the following headings to your Rmd and replace the text below with your own content based on overlap with the course and your interests:
## Content What burning environmental question(s) would you like to address? Feel free to provide group project, dissertation, and/or personal interest. What's the study area? ## Techniques What techniques from the course do you think will be most applicable? ## Data What data have you already identified? Feel free to provide a link and/or details on the variables of interest. -
For details on Rmarkdown syntax, see:
- RStudio menu Help > Markdown Quick Reference
- RStudio menu Help > Cheatsheets > R Markdown Cheat Sheet
- RStudio menu Help > Cheatsheets > R Markdown Reference Guide
-
For instance, you could add an image into
students/images/cool_idea.pngusing Mac Finder or Windows Explorer, and incorporate this into yourstudents/<username>.Rmdby adding a line like: -
For this to work on the http://ucsb-bren.github.io/env-info site, you’ll need to commit and push the knitted
<username>.htmlandimages/cool_idea.pngfiles. Play with formatting to add at least one italic, bold, list, link, and image. -
Next, add a table of contents by replacing the front matter line (in YAML 3):
output: html_documentwith
output: html_document: toc: true toc_depth: 2 -
Next, add a chunk of R code to read a csv 4 data file and output a summary, like:
```{r} # read csv d = read.csv('bbest_ports.csv') # output summary summary(d) ```Try to use data relevant to your question of interest, and be sure to copy the csv data file into the
students/datafolder, preferably with a file name like<username>_<dataname>.csv. If you have trouble finding data, explore the links in Data. -
Be sure to run the “Knit HTML” on your
students/<username>.Rmdto generate the final desiredstudents/<username>.html
-
-
Commit, push and pull request your changes, per Github Workflow. This is how you’ll turn in this assignment.
Review. We can provide line-by-line feedback directly within the pull request as part of a code review. You could even follow up with submitting corrections by pushing fixes up to your fork, which will be reflected in the pull request. When we’re finished giving feedback, we’ll close the pull request and leave a
 in the final comment.
in the final comment.
Resources
Fixing rpostback-askpass error
If you get this rpostback-askpass error on a Mac when pushing in RStudio, see rpostback-askpass error on Mac doing Git Push from RStudio to Github · Issue #2 · ucsb-bren/env-info:
error: unable to read askpass response from 'rpostback-askpass'
fatal: could not read Username for 'https://github.com': Device not configured
Git, Github and RStudio
- Git and GitHub cheat sheet
- Git and GitHub with RStudio
- PLOS Computational Biology: A Quick Introduction to Version Control with Git and GitHub
Rmarkdown
- Markdown quick reference
- R Markdown cheat sheet
- R Markdown reference guide
- Mastering Markdown - GitHub guides
Footnotes
json
JavaScript Object Notation (json) is a lightweight data format, which is both human and machine readable with complex hierarchies like XML, but more compact (and less explicit with tags).
jekyll
Jekyll is a static site generator used by Github Pages (the website hosting capacity of Github, since default view of HTML is as code not rendered form) using the liquid templating language which has limited data file support for JSON in the _data folder for iterating through JSON file objects like in students/index.md and wrapping the template in layouts/default.html which uses the _includes to provide a common navigational bar for the site to yield the final students/index.html.
yaml
YAML is a human readable format for storing variables of various types (single values, lists, arrays) in a language agnostic manner. It’s commonly used in configuration files, and any modern language would have a library for reading and writing this format (eg yaml for R).
csv
CSV, Comma-separated_value, files store data in a human and machine readable format in which rows of data are seperated by a newline, and columns by a comma. This format is probably the most widespread for sharing tabular data, and is read by most database and spreadsheet programs, including Excel. CSV files are also nicely rendered in Github with column formatting, searching and even line-by-line linking. An emerging standard for tabular data stores data in CSV form and the metadata (ie variable description, variable type, dataset source, citation, etc) as JSON.